Vertical Table Support
Relational Tables vs. Vertical Tables
The following sections describe the differences between relational tables and vertical tables as well as discuss when and why each type should be used.
Relational Table
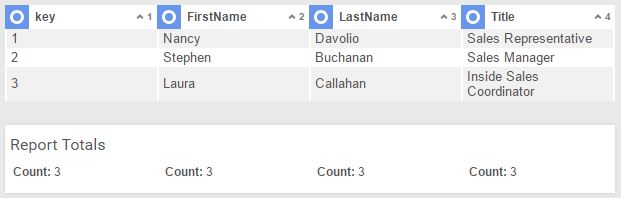
In a relational table, each row contains a group of common data fields, associated by a unique key. Take the following table, for example:
| Key | FirstName | LastName | Title |
|---|---|---|---|
| 1 | Nancy | Davolio | Sales Representative |
| 2 | Steven | Buchanan | Sales Manager |
| 3 | Laura | Callahan | Inside Sales Coordinator |
Each row is a unique “person,” who has values for the data fields FirstName, LastName, and Title. Rows are distinguished by a unique key (which often is, but does not always have to be, a discrete field).
This table format can efficiently hold a large quantity of unique values, which can be efficiently joined with other tables by associating unique keys. This is how the relational model works, and is the basis for this application’s functionality.
Vertical Table
In a vertical table, each row contains one value for one data field for a unique key.
The following table contains the same data as the relational table, but is organized vertically.
| Key Value | Field Name | Value | Data Type |
|---|---|---|---|
| 1 | LastName | Davolio | 0 |
| 1 | FirstName | Nancy | 0 |
| 1 | Title | Sales Representative | 0 |
| 2 | FirstName | Steven | 0 |
| 3 | Title | Inside Sales Coordinator | 0 |
| 3 | LastName | Callahan | 0 |
| 2 | LastName | Buchanan | 0 |
| 2 | Title | Sales Manager | 0 |
| 3 | FirstName | Laura | 0 |
In this table, the names of the data fields are described in a Field Name column, and the value for the fields is described in a Value column. The Key Value is used in order to know what data belongs together. For instance, ‘Davolio’, ‘Nancy‘, and ‘Sales Representative‘ belong together in the same data row, so they all have the same key value. The field rows do not need to be adjacent; the table is sorted/grouped by Key Value after it is retrieved.
The table can also have an optional Data Type, which gives information on how to format fields. Data Types are defined by integers, describing the following types:
- String
- Date
- Integer
- Boolean
- Numeric
- Float
- Decimal
- GUID
- DateTime
- Time
- Image
This type of table is often used in situations where the data fields are not known at design time, or are very dynamic. An example of this is for user defined data, which allows an end user to add their own data fields. Since the data fields can be added at any time, their names are often stored as rows as shown above.
The main advantage of a vertical table is that data fields are defined in rows, not columns. Vertical tables are more predictable, since they can only grow vertically, not horizontally. The disadvantage is that they can grow exponentially larger, by rows, than relational tables. And to join them to other tables, they require a query-time transformation, which can be computationally expensive.
Transforming Vertical Tables
Note
This method of transformation is only supported by Database Table and View data objects. For other object types, such as Stored Procedures and Functions, the transformation must be done in the object code. File sources, such as Excel and CSV, and programmable sources, such as web services and assemblies, are not supported.
Vertical tables can be configured “horizontally” in the application, allowing the tables to be joined and otherwise used as normal.
Some additional information must be supplied in the configuration XML. This cannot currently be done in the Admin Console.
To transform a vertical table:
- Add the table to the application’s configuration either through the Admin Console or by directly editing the XML configuration file. See Data Objects for instructions. If the table already exists, skip to step 2.
Note
The unique key field is the column containing the key values.
- Edit the configuration file in a text or XML editor.
- Within the table
<entity>add a<transform>element with the following nodes:-
col_name: The name of the column which contains the data field names -
val_name: The name of the column which contains the data values -
datatype_name: Optional: The name of a column which contains the data types. If this does not exist, you can set the data types using Column Metadata. Otherwise, the application will interpret values as strings unless formatted on the report.Note
In order for vertical tables to properly support Date and DateTime values are being used, their formatting must be specified. This value can be specified in the Date Format String field located in the Column Metadata menu.
-
non_transform_col: Optional: Any number of nodes which contains the name and optional data type of any fields that should not be transformed, whose values can be shown as-is along with the value on a report.
-
Example
<entity>
<entity_name>TransformTable</entity_name>
<db_name>transform_table</db_name>
<datasource_id>0</datasource_id>
<object_type>table</object_type>
<key>
<col_name>key_value</col_name>
</key>
<transform>
<col_name>field_name</col_name>
<val_name>field_value</val_name>
<datatype_name>data_type</datatype_name>
<non_transform_col>
<col_name>effective_date</col_name>
<data_type>1</data_type>
</non_transform_col>
</transform>
</entity>
Advanced Join Support
Prior to v2018.1, vertical table transformations were done in application memory, after the initial data was returned from the database. This prevented certain features from working properly with vertical tables, such as advanced joins (which cannot be applied in memory).
As of v2018.1+, this transformation occurs differently. The application now generates a transformed SQL query, then retrieves the transformed table directly from the database. This has the effect of allowing other forms of database processing to function properly with transformed vertical tables. Transformed tables may also see increased performance as a result.
Note
Non-transform columns must be joined in memory, and as such cannot utilize advanced joins.
Additionally, column tenancy and role filters now also apply to column schema queries, not just data queries. (This behavior only exists for vertical tables because row based filtering can affect the available columns when the table is pivoted).
If any problems occur with the new behavior, set the hidden configuration flag <canjointransformobjectsindb> to False to revert to the legacy behavior.
